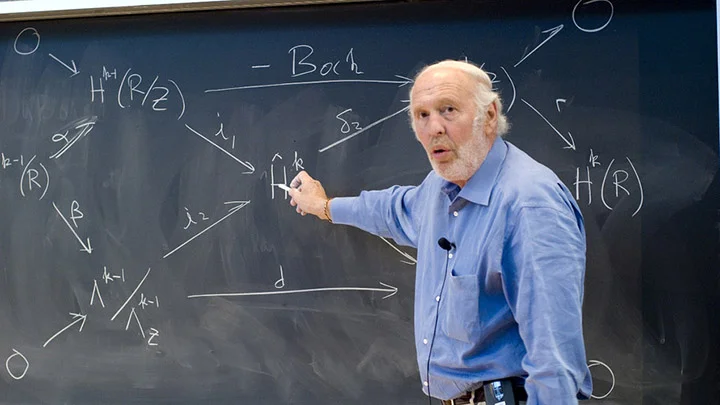在AI创业公司工作快一年,总体的体验非常积极。这里的工作节奏极快,适合喜欢追求最大影响力、喜欢将产品快速推向用户并及时迭代的工程师。同事们都非常资深且易于合作,几乎没有大公司常见的办公室政治,大大减少了因人际关系而耗费的精力。此外,整个AI行业的技术迭代速度非常快,尤其在顶尖公司里,能够近距离地看到外界难以窥见的研发过程。科研不是一天完成的,产品也不是短期就能打磨完善,支持亿万用户的Infra更非一蹴而就。站在第一线感受边开飞机引擎边冒烟,然后跟团队一起修引擎的状态,让我不禁回想起十年前在Uber China Growth的日子。但不同的是,那时的我刚刚踏入职场,更看重「Work hard, play harder」。如今作为团队中的老码农,少了玩乐的部分,除了努力工作外,更需要规划团队未来的方向,把“饼”做得更大更圆。
Zuck提到加入「编程」的另一点是会帮助大模型训练更好的「推理」能力。比如你跟大模型交流的时候,即使应用场景不是编程,是一个企业的客服。更好的推理能力能够帮助大模型把一个问题转换成对「实现一个目标的」思考,然后进一步变成一个「多步骤」的互动。然后Zuck认为推理能力是大模型在市场上保持竞争力非常重要的一个因素,所以即使Meta的AI产品不直接跟写程序有关,公司也会加大大模型在编程方面的训练。这让我想到前段时间Elon Musk的一条Tweet:「Whoa, I just realized that raising a kid is basically 18 years of prompt engineering 🤯」,他把养育小孩比做Prompt Engineering,进一步延展这个想法,早点学习编程是不是也能帮助小孩更好地掌握「推理事情」的能力呢?
另一个是Tony Xu在Good Company的采访,采访里面提到DoorDash最开始成立的时候,MVP就是一个网站,用户打电话点外卖,电话的另一头是创始人团队成员接到订单之后,亲自去餐馆下单,亲自去餐馆取餐,亲自去把外卖送到客户的手里。当时的「dispatch system」就是几个团队成员用的iPhone的「Find My Friends」,后来的故事大家也都知道了。我也早都知道创业早期特别需要hustle,YC也特别强调过创业初期需要创始人去做「不一定能scale但是客户热爱的生意」,道理都懂。但是随着年纪增长,时间成本和机会成本也都不再像20岁出头的大学生,即是你知道创业一开始很可能要去做「不一定能scale」的事情,但是又有多少决心和勇气去做「外卖骑手」呢?
这期几个嘉宾聊了 Western countries big cities 普遍的流浪汉问题,Chamath去了一趟巴黎觉得「卧槽」巴黎跟旧金山也差不多,出门还要一直担心有没有人会来偷他抢他的手表钱包,所以美国其实也不差嘛。然后Friedberg 问了他一个问题你觉得跟亚洲城市比呢(新加坡,东京,中国的城市,etc.),他才意识到好像这也不是一个世界性普遍的问题,因为亚洲的城市安全性好太多了吧 。Sacks才一针见血地指出这是过去十多年来西方执政政府大吹的「左风」导致的结果。
这期还聊了 AI 和音乐创作。如果读者你还没听说过Suno,赶紧打开 YouTube 搜一个视频看看,保证惊掉你的下巴。故事背景是一群音乐人写了个信,大致意思是AI偷了他们的作品之类的,然后马上有议员出来说要提案「AI训练数据用到了创作者的作品需要付钱」。然后几个嘉宾针对AI模型的训练用到创作者的数据是否需要付钱展开了辩论。Friedberg的观点是「不用」,因为就像所有的音乐人的创作,大家都是在听过无数首前人的作品的基础上,被「Inspire」然后再创作出自己的原创作品,所以如果有剽窃的嫌疑,应该针对模型的「输出」做监管。Chamath的观点则是,如果只对Output做监管,那肯定没法监督,这些创作者就等着早日被全部取代吧。Sakcs最后比较中间,意思是AI肯定不会完全用人类一样的监管方式,不过现在提监管还是有点早,最终应该还是会讨论出一个中间的方式来监督。
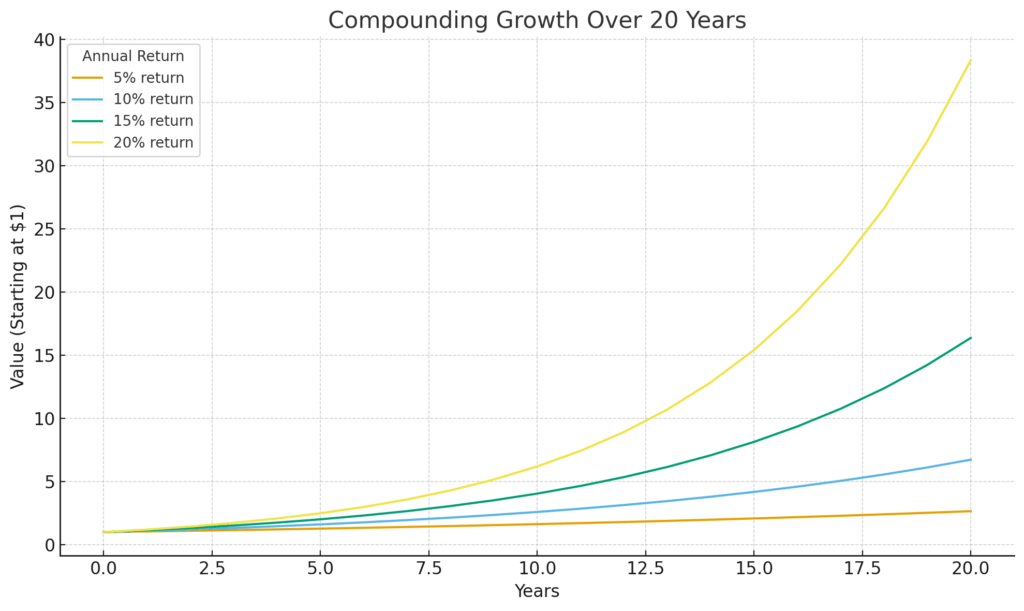
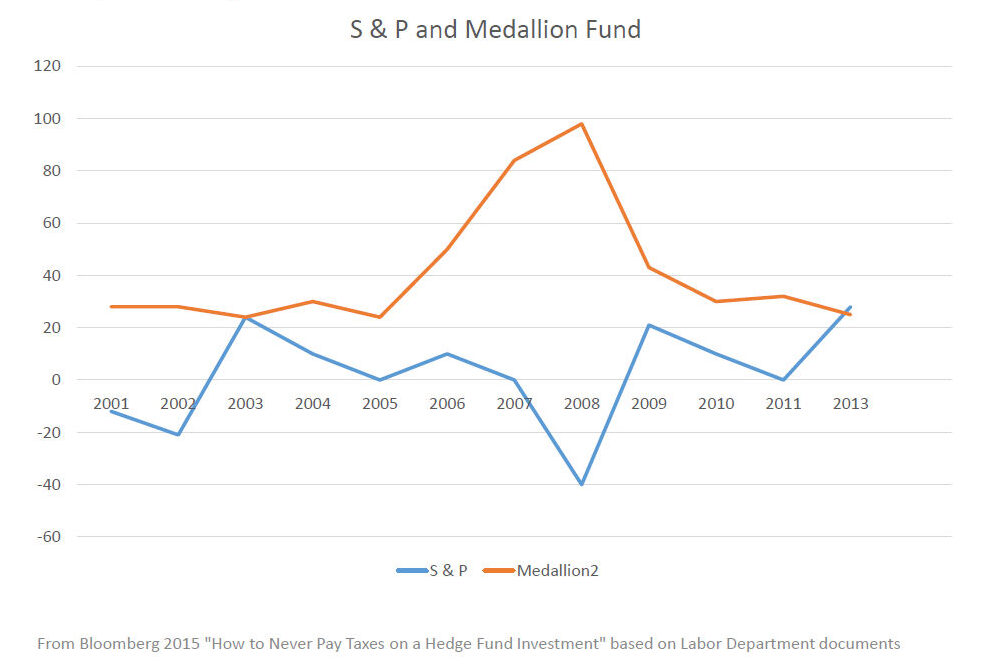
文艺复兴基金与其说是一个金融公司,其实更像是一个Research House,根据他们网站介绍,公司300来个员工有90多个数学、物理和计算机科学领域的博士。西蒙斯自己就拿过拓扑学的奥斯瓦尔德·维布伦几何学奖(Oswald Veblen Prize in Geometry),跟陈省身合作提出的「陈-西蒙斯理论」后来也成为了量子物理学不断被引用的理论框架。公司的早期关键算法设计师,也是后来西蒙斯退休的时候的Co-CEO Peter Brown 和 Robert Mercer在加入文艺复兴基金之前是在IBM开发曾经深蓝计算机的计算机科学家。公司早期另一个算法设计师和数学家Elwyn Berlekamp的博士生导师则是现代信息学之父克劳德·香农。而前面提到的Peter Brown的博士生导师则是现今深度学习的开创者之一Geoffrey Hinton。 对这些数学、物理和计算机领域的研究员来说,所有的投资标的都成为了一个个的数据点,他们的目标是如何打造效率最高的信息处理算法,和能够处理超级大量信息的计算系统,最终通过数据和模型赢下市场。回头看,他们做的很多事情其实都是现在许多量化交易公司在做的事情,甚至是很多科技公司在机器学习或者人工智能领域都在做的事情。区别只是文艺复兴已经做了40年。
节假日又听完了一期Lex的采访,这次主角是Amazon的创始人和前CEO Jeff Bezos,也是航天公司Blue Origin的创始人。采访分为两大部分,一块讲了他创建Blue Origin的初衷和其中现阶段火箭发射技术的讨论,另一大块讲了他在创建Amazon的过程中自己对公司文化实现的想法和这些文化如何影响了Amazon公司的日常运营。